TRUEBench von Samsung prüft KI-Produktivität im Arbeitsalltag
KI-Benchmarks hatten lange Zeit Schwierigkeiten, die tatsächliche Nutzung durch Menschen realistisch abzubilden. Viele Tests konzentrieren sich nach wie vor auf englischsprachige Frage-Antwort-Szenarien, die zwar auf dem Papier solide wirken, jedoch kaum die Vielfalt der Aufgaben widerspiegeln, die im Arbeitsalltag relevant sind. Mit TRUEBench – kurz für Trustworthy Real-world Usage Evaluation Benchmark – hat Samsung nun ein neues Verfahren vorgestellt, das die Leistungsfähigkeit von KI-Systemen näher an realen Büroanforderungen misst.
TRUEBench geht deutlich über einfache Quizfragen hinaus. Die Tests umfassen unter anderem Textzusammenfassungen, Übersetzungen in zwölf Sprachen, Datenanalysen und mehrstufige Anweisungen, bei denen die KI den Kontext über längere Passagen hinweg wahren muss. Insgesamt wurden 2.485 Testsätze in zehn Kategorien und 46 Unterkategorien entwickelt – von Eingaben mit nur wenigen Zeichen bis hin zu Texten mit über 20.000 Zeichen. Ziel ist es, sowohl kurze Befehle als auch komplexe Geschäftsberichte realistisch zu simulieren.
Paul (Kyungwhoon) Cheun, CTO der DX-Sparte bei Samsung Electronics und Leiter von Samsung Research, erklärte: „Samsung Research bringt durch seine praktische KI-Erfahrung fundiertes Fachwissen und einen klaren Wettbewerbsvorteil mit. Wir erwarten, dass TRUEBench neue Bewertungsstandards für Produktivität setzt und gleichzeitig die technologische Führungsrolle von Samsung stärkt.“
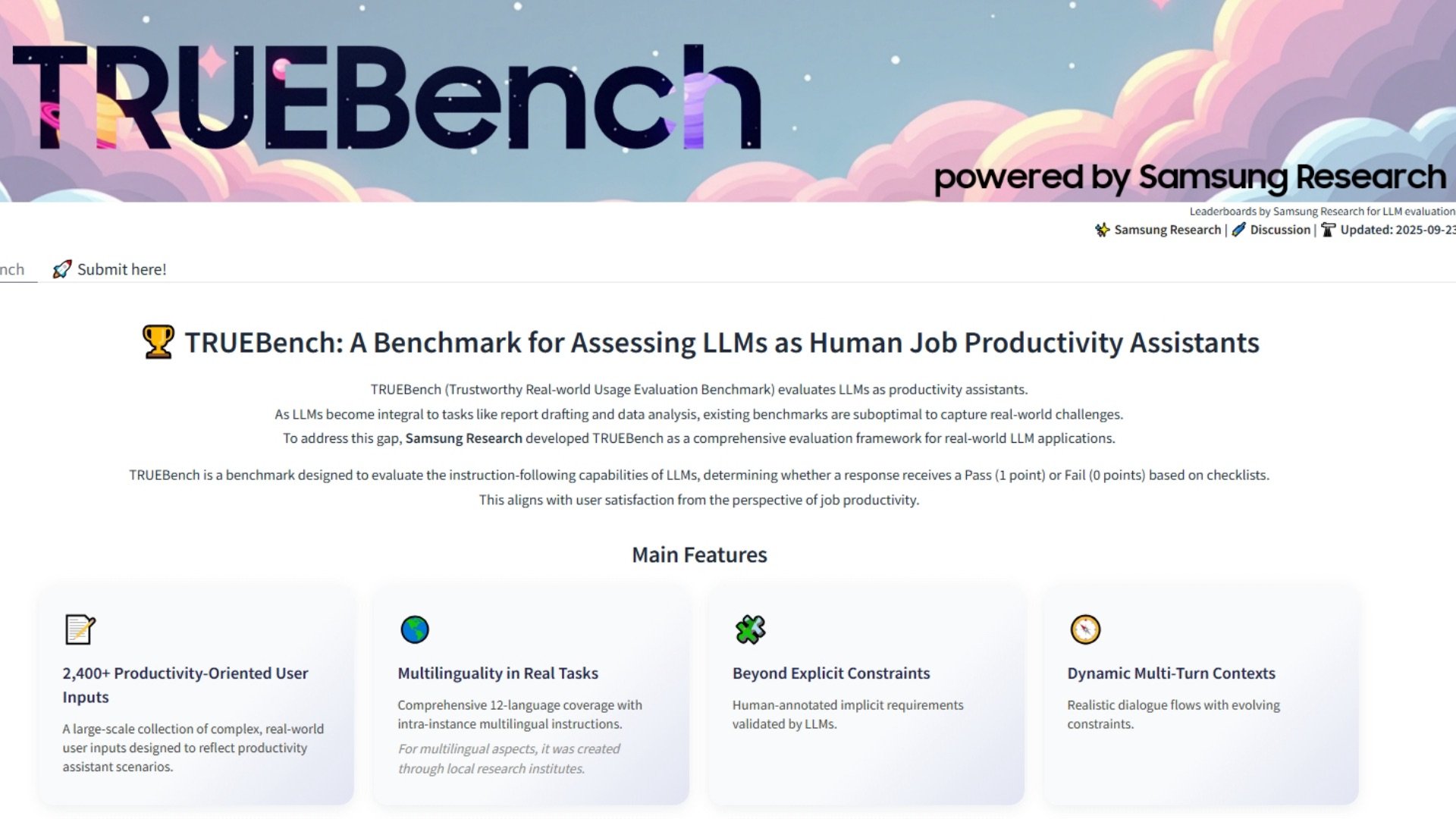
Damit ein Modell einen Test besteht, muss es alle erforderlichen Bedingungen erfüllen – einschließlich impliziter Anforderungen, die widerspiegeln, was eine vernünftige Person erwarten würde, auch wenn diese nicht ausdrücklich genannt werden. Diese Alles-oder-Nichts-Methode macht die Bewertung zwar strenger, spiegelt jedoch besser wider, wie man in der Praxis entscheiden würde, ob ein Ergebnis wirklich nützlich ist. Samsung entwickelte die Regeln, indem menschliche Eingaben mit KI-Prüfungen kombiniert wurden: Menschliche Annotatoren legten die Ausgangsbedingungen fest, die KI identifizierte Widersprüche oder Inkonsistenzen, und anschließend verfeinerten Menschen das Framework, bevor es endgültig festgelegt wurde. Nach Fertigstellung konnte die Bewertung dann automatisiert und in großem Maßstab durchgeführt werden.
Darüber hinaus hat Samsung den Datensatz, die Ranglisten und die Ausgabestatistiken über Hugging Face veröffentlicht. Nutzer können bis zu fünf Modelle direkt vergleichen und sehen, wie ihre Ergebnisse abschneiden. Diese Transparenz ermöglicht es Entwicklern, Forschern und Anwendern, den Benchmark selbst zu überprüfen, anstatt sich ausschließlich auf Samsungs Angaben zu verlassen.
Der Benchmark ist jedoch nicht fehlerfrei. Die Festlegung der Regeln bringt immer ein gewisses Maß an Voreingenommenheit mit sich, und die strikte Forderung nach vollständigem Erfolg führt dazu, dass teilweise korrekte, dennoch hilfreiche Antworten als Fehlschläge gewertet werden. Zwar unterstützt TRUEBench mehr Sprachen als die meisten bestehenden Tests, die Leistung variiert jedoch, insbesondere bei Sprachen mit wenigen Trainingsdaten. Außerdem richtet sich der Testsatz auf allgemeine Geschäftsaufgaben, sodass hochspezialisierte Bereiche wie Recht, Medizin oder wissenschaftliche Forschung möglicherweise nicht vollständig abgedeckt werden.
Quelle(n)

