Mistral AI stellt Magistral vor – das erste eigene KI-Modell mit logischem Denkvermögen

Das französische Unternehmen Mistral AI hat mit Magistral ein neues KI-Modell vorgestellt, das speziell auf logisches Denken ausgelegt ist. Im Gegensatz zu herkömmlichen KI-Modellen nimmt sich Magistral mehr Zeit, um Probleme zu analysieren, Informationen zu recherchieren und durchdachte Antworten zu formulieren. Besonders für regulierte Branchen wie Finanzen, Recht und Medizin bietet das Modell einen wichtigen Vorteil: die Rückverfolgbarkeit seiner Argumentation, was die Einhaltung strenger Compliance-Vorgaben erleichtert.
Magistral positioniert sich als europäische Alternative zu führenden KI-Modellen aus den USA (etwa OpenAI, Perplexity, Anthropic, Meta und Grok) und China (DeepSeek), die derzeit die Ranglisten auf dem LMArena AI Leaderboard anführen. Der französische Präsident Emmanuel Macron bezeichnete Mistral AI kürzlich als Beispiel für technologische Souveränität und kündigte ein nationales KI-Rechenzentrumsprojekt mit einem Investitionsvolumen von 30 bis 50 Milliarden Euro an – ein strategischer Schritt, um Frankreichs Unabhängigkeit in der globalen KI-Landschaft zu stärken.
Mistral AI hat Magistral in zwei Versionen veröffentlicht – ein kleineres Open-Source-KI-Modell mit 24 Milliarden Parametern namens Magistral Small sowie ein leistungsstärkeres Modell namens Magistral Medium für Unternehmen und Privatpersonen, die über die API oder durch Abonnements des webbasierten Chatbots Le Chat darauf zugreifen. Magistral Medium wird zudem auf KI-Cloud-Plattformen wie Microsoft Azure AI bereitgestellt.
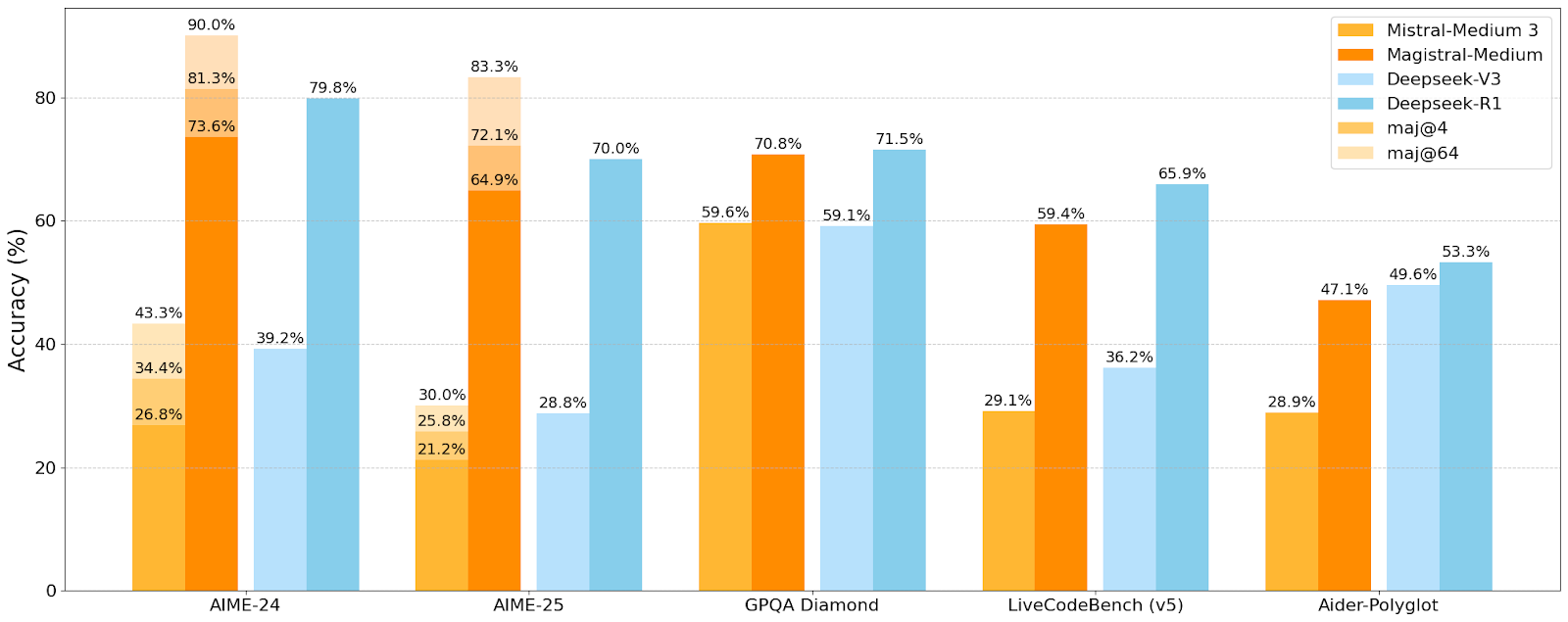
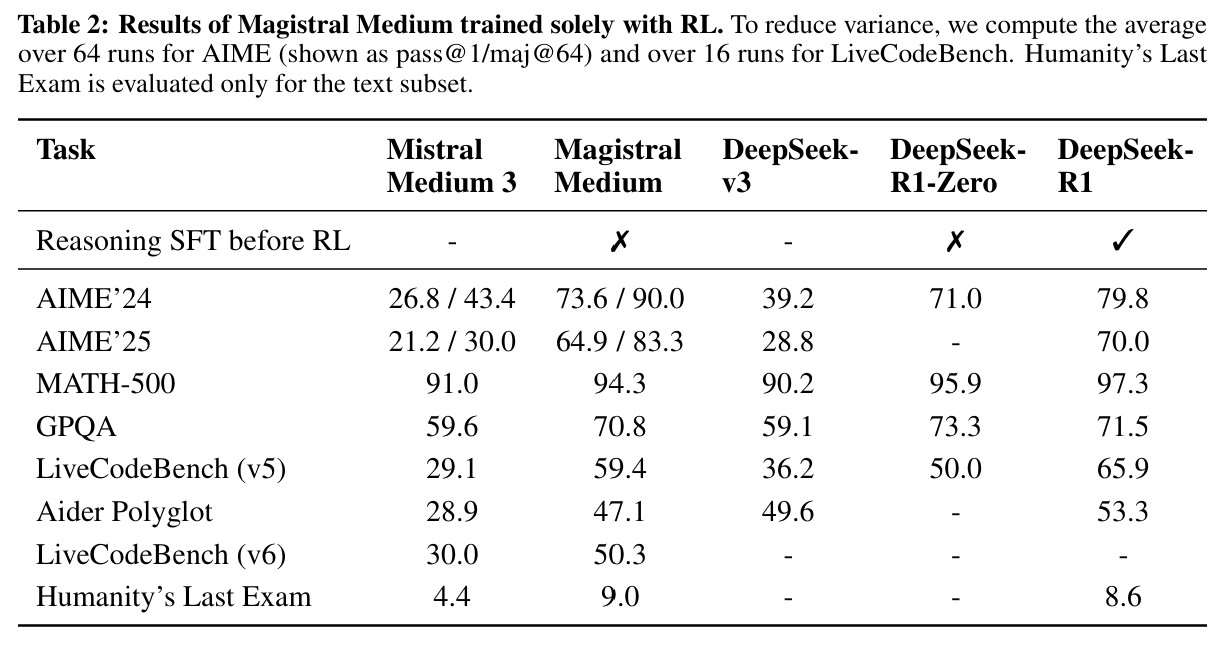
Magistral Medium wird auch über Plattformen wie Microsoft Azure AI angeboten. Seine Leistung liegt auf einem Niveau mit DeepSeek R1, einem chinesischen Modell für logisches Schlussfolgern, während Magistral Small naturgemäß etwas schwächer abschneidet. In der Webanwendung Le Chat nutzt Magistral standardmäßig den Flash-Antwort-Modus, der besonders schnelle Reaktionszeiten ermöglicht. Laut Mistral AI verarbeitet das Modell Informationstoken bis zu zehnmal schneller als die Konkurrenz – belastbare Vergleichsdaten wurden allerdings nicht veröffentlicht. Wie bei anderen Chatbots erscheinen Antworten meist innerhalb von ein bis zwei Sekunden.
Wer hingegen nachvollziehbare Argumentationsschritte sehen möchte, sollte den Think-Modus aktivieren. In diesem Modus nimmt sich die KI mehr Zeit und dokumentiert ihre Überlegungen Schritt für Schritt – ideal zur Überprüfung und für komplexere Aufgaben.
Nutzer, die das Magistral Small-Modell lokal über Hugging Face betreiben und anpassen möchten, sollten über eine entsprechend leistungsfähige GPU verfügen – etwa eine Nvidia RTX 5090, die beispielsweise bei Amazon erhältlich ist.