CheckMag | Keine GPU? Kein Problem: Eigenes LLM hosten macht mehr Spaß als zensierte Angebote großer Anbieter

Was genau mit den eigenen Daten passiert, wenn man eine Anfrage an eine KI stellt, weiß letztlich kaum jemand. Klar ist aber: Was auch immer damit geschieht, wirklich im eigenen Besitz sind diese Daten danach nicht mehr.
Neben der Bild- und Videogenerierung ist das Hosting eines eigenen LLM überraschend einfach und bringt einige Vorteile gegenüber den Angeboten der großen Anbieter mit sich – besonders dann, wenn man mit Large Language Models experimentieren möchte, ohne seine Daten an Big Tech weiterzugeben.
Der wichtigste Punkt: Ganz gleich, wofür das Modell genutzt wird, sämtliche Daten bleiben unter eigener Kontrolle. Allein das ist schon ein klarer Vorteil, wenn man seine Daten nicht an Dritte übergeben möchte. Hinzu kommt, dass sich praktisch jedes beliebige Modell verwenden lässt – ob Deepseek, Gemma2 oder GPT. Ein weiterer Vorteil besteht darin, auch Versionen nutzen zu können, die bestimmte Arten von Anfragen nicht einschränken.
KoboldCPP ist ein einfach zu bedienendes KI-Tool zur Textgenerierung, das aus einer einzigen ausführbaren Datei besteht und für GGUF- und GGML-Modelle ausgelegt ist. Es unterstützt sowohl GPU als auch CPU und kann als spezialisiertes Backend für KI-Storytelling und Chats dienen. KoboldCPP kann über GitHub heruntergeladen werden und ist für Windows, Linux, Mac sowie Docker verfügbar.
Wird das Ganze in einem Container gehostet, lässt sich das LLM ohne großen Aufwand für jedes Gerät im eigenen Netzwerk verfügbar machen. Für die wichtigsten Plattformen, darunter Unraid und TrueNAS, gibt es bereits fertige Vorlagen. Dasselbe ist auch mit anderen Installationen möglich, sofern die nötigen Regeln in der Firewall gesetzt werden.
Erste Schritte
Sobald die gewünschte Plattform feststeht, muss zunächst entschieden werden, welches Modell genutzt werden soll. Die beste Anlaufstelle dafür ist Hugging Face. Die Modelle müssen dabei im GGUF-Format vorliegen.
Wer D&D-Szenarien hosten möchte, sollte auf jeden Fall ein unzensiertes Modell wählen. Andernfalls wird das LLM sich früher oder später weigern, einer Figur Schaden zuzufügen, was zu unerwünschten Ergebnissen führen kann.
Einige Modelle wie Deepseek und Claude neigen dazu, „nachzudenken“, also den gesamten Denkprozess zu einer Anfrage auszugeben. Mit einer GPU, die die Hauptarbeit übernimmt, mag das noch in Ordnung sein, ohne GPU verlangsamt es den Ablauf jedoch deutlich. Hier hilft letztlich nur Ausprobieren, um ein passendes Modell zu finden. Gemma2 ist dafür ein guter Ausgangspunkt.
Auf der jeweiligen Dateiseite muss dann die URL kopiert werden, die zur GGUF-Datei führt. Viele Modelle gibt es in mehreren Größen, daher sollte eine Variante gewählt werden, die im Rahmen des verfügbaren Arbeitsspeichers bleibt.
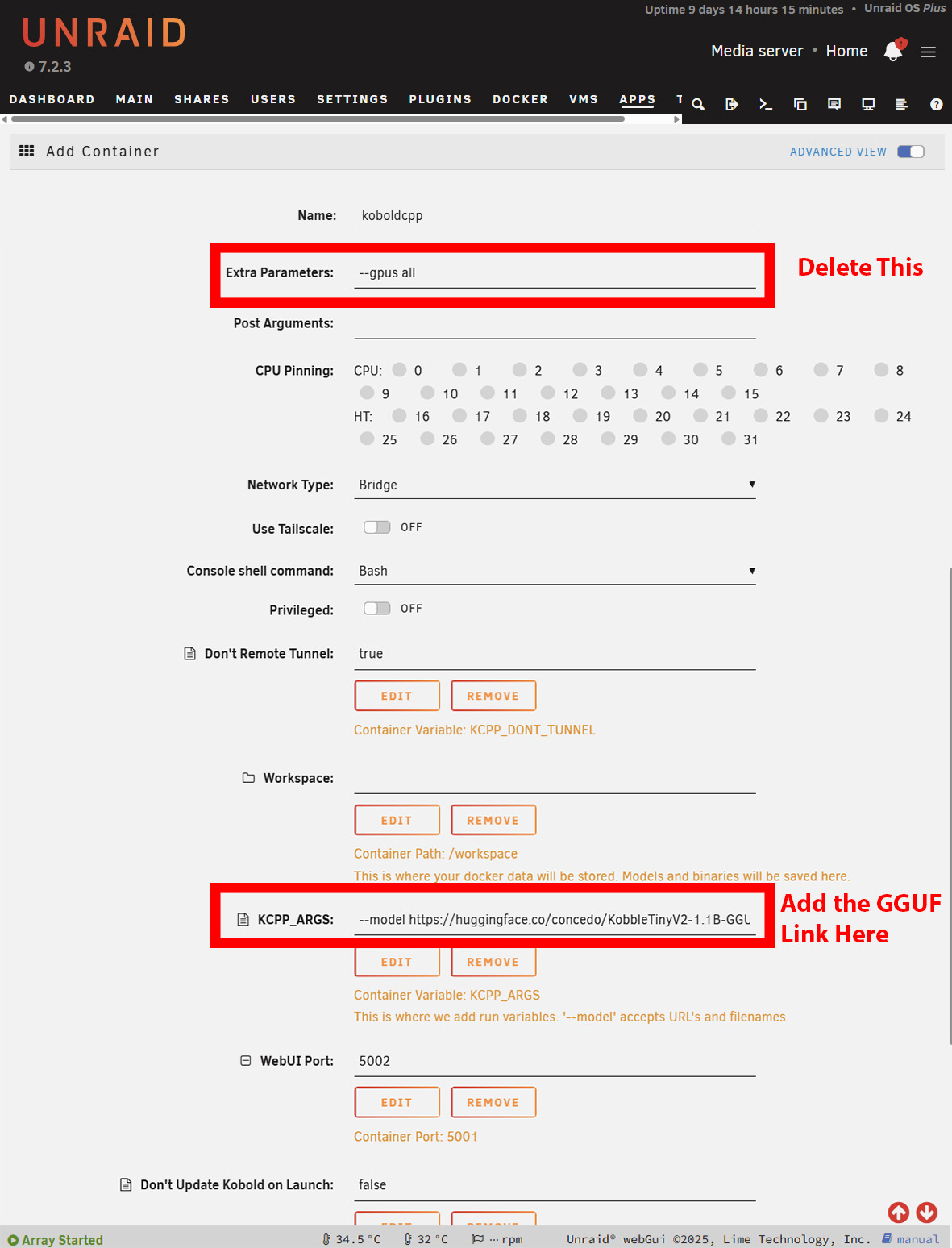
Die Installation unter Windows läuft weitgehend genauso ab. Wird das Modell ohne GPU genutzt, muss allerdings die NoCUDA-Version heruntergeladen werden. Der Start kann etwas dauern, da KoboldCPP zunächst das Modell herunterlädt, bevor die Benutzeroberfläche angezeigt wird. Unter Windows ist das gut erkennbar, bei Unraid oder TrueNAS muss dagegen das Log geöffnet werden, um den Download-Fortschritt zu sehen. Unter Unraid kann es zudem nötig sein, den verfügbaren Speicherplatz für Docker-Container zu erhöhen – je nachdem, wie groß das gewählte Modell ist.
KoboldCPP bietet vier verschiedene Oberflächenmodi: Instruct, Story, Chat und Adventure.
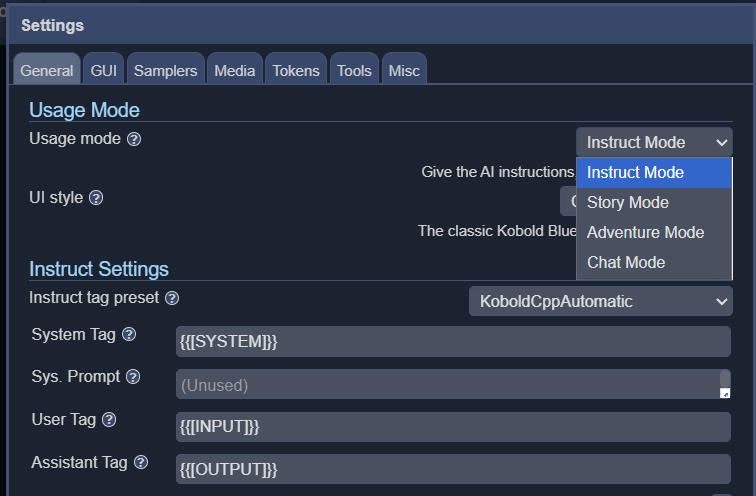
Es ist zwar beim besten Willen nicht besonders schnell, doch die Textgenerierung liegt nur leicht unter dem durchschnittlichen Lesetempo. Für D&D-Szenarien auf einem 16-Kern-AMD 5950X (derzeit rund 300 Euro bei Amazon) ist das aber absolut brauchbar und dürfte auf moderneren CPUs wahrscheinlich noch schneller laufen. Je mehr Kerne zur Verfügung stehen, desto besser. Eine ordentliche Menge Arbeitsspeicher ermöglicht zudem den Einsatz größerer Modelle, wobei 16 GB in der Regel ausreichen sollten. Auch Größe und Typ des gewählten Modells haben erheblichen Einfluss auf die Generierungsgeschwindigkeit. Mit einem schlankeren Modell lässt sich das Tempo spürbar erhöhen.
Für das bestmögliche Erlebnis sind Large Language Models mit einer GPU natürlich die beste Wahl. Wer aber einfach ein eigenes LLM ausprobieren, die Einschränkungen von ChatGPT, Claude oder Gemini umgehen oder seine Daten nicht diesen Diensten anvertrauen möchte, braucht für den Einstieg keine besondere Hardware – und bekommt trotzdem eine ordentlich nutzbare Erfahrung.

