Dieses praktische Open Source Tool extrahiert für mich Text aus allem, sogar Videos und Bildern
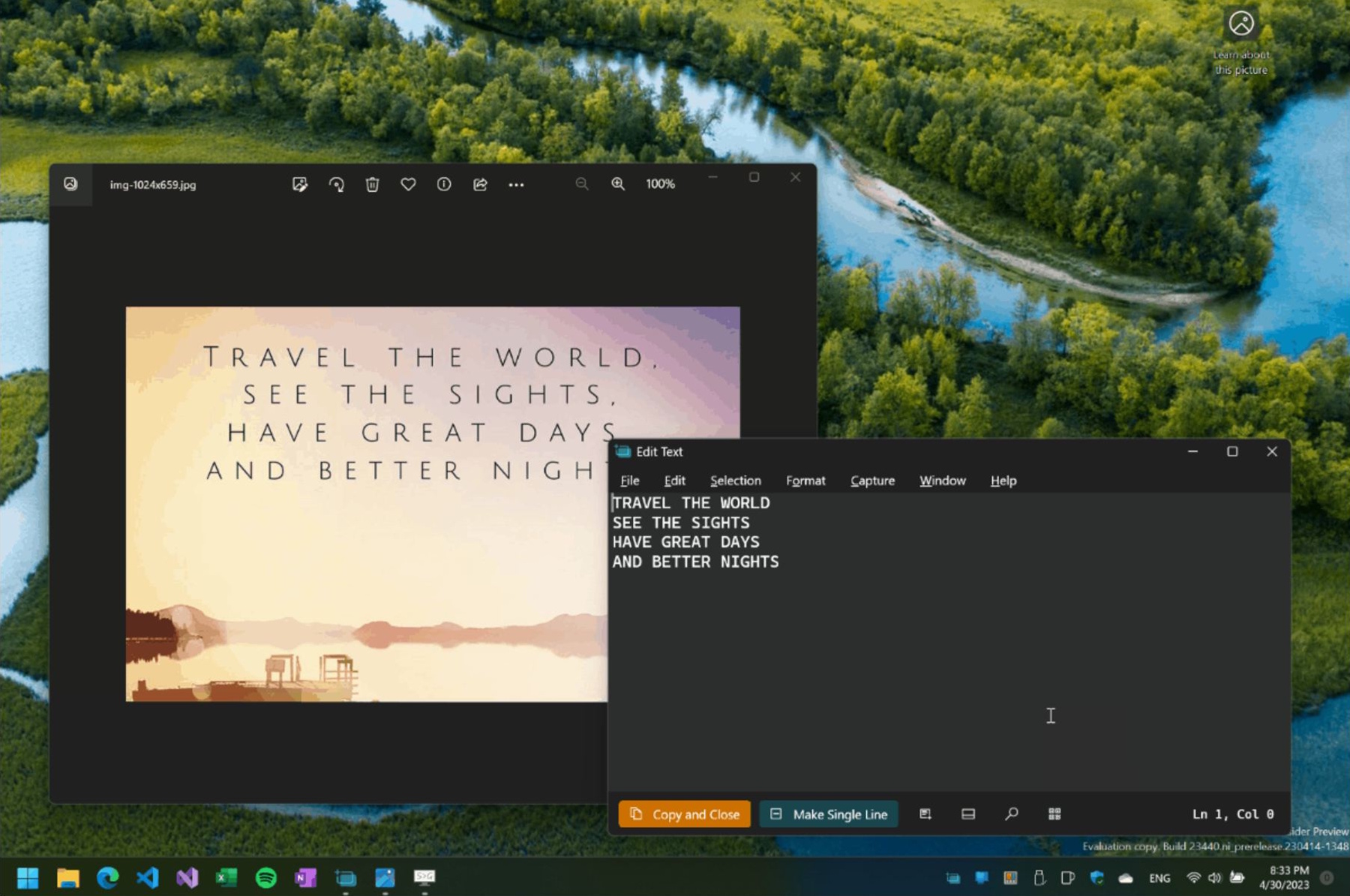
Kennt das noch wer? Aus den meisten pdf-Dateien lässt sich Text einfach herauskopieren. Dann aber wieder gibt es pdf-Dateien, die offenbar nicht aus einem Textdokument heraus erstellt wurden, sondern offenbar aus eingescannten Fotos, obwohl die Inhalte aus Text bestehen. Dann ist es ärgerlich, dass man daraus keinen Text markieren und herauskopieren kann – jedenfalls nicht ohne weiteres.
Anderes Beispiel: Ich schaue ein Video über die besten Crawler (das sind ferngesteuerte RC-Autos, die speziell dafür gebaut sind, extrem schwieriges Gelände zu bewältigen, z.B. so etwas hier) in einer bestimmten Preisklasse, mein Kind interessiert sich dafür. Die teils kryptischen Bezeichnungen der Modellautos sind zwar im Video eingeblendet, tauchen aber leider nicht als kopierbarer Text in der Videobeschreibung auf.
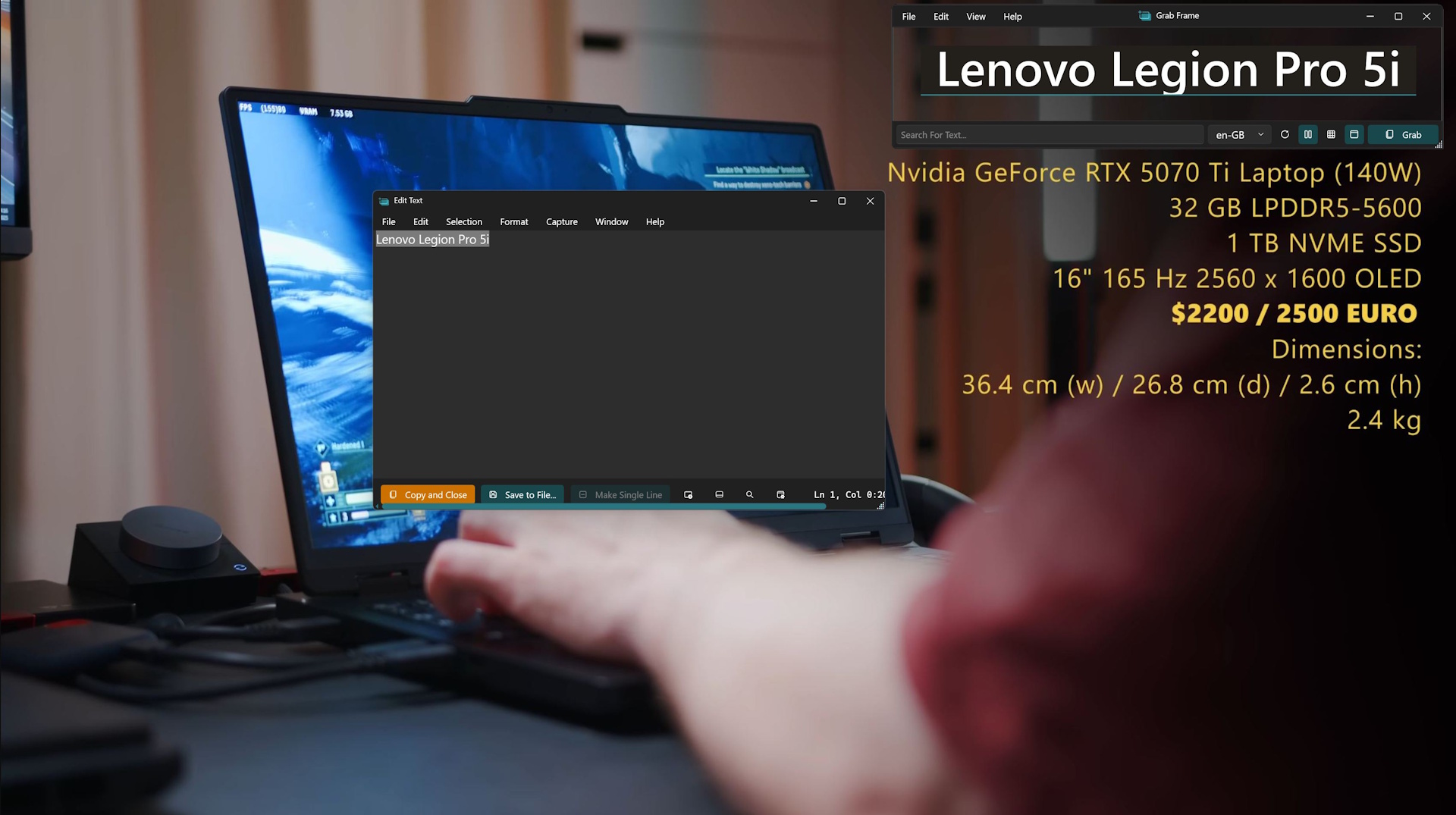
Hier kommt Text Grab ins Spiel: Das Tool ist Open Source, über Github herunterladbar und für Windows X86 und ARM64-PCs erhältlich und tut genau das, was ich bei den vorherigen Beispielen gebrauchen könnte: Es extrahiert Text aus Bildern, Videos, Foto-pdfs und quasi jedweder anderen Quelle auf dem Bildschirm.
Dabei ist die Bedienung denkbar einfach, denn das Tool funktioniert wie ein übliches Snapshot-Tool. Das bedeutet man macht einfach einen Screenshot vom Bildschirminhalt oder einem bestimmten Bereich auf dem Bildschirm und schon erkennt das Tool den enthaltenen Text und kopiert diesen automatisch in die Zwischenablage. Wie bei einem Screenshot-Tool kann man natürlich Tastenkombinationen festlegen, um den Bildschirm oder bestimmte Bereiche abzufotografieren. Am besten stellt man in den Einstellungen ein, dass es im Hintergrund läuft, dann funktionieren auch die Shortcuts. Ansonsten muss man das Programm jedes Mal manuell aufrufen.
Die 74 MB kleine App hat mehrere Modi: Man kann den ganzen Screen fotografieren und nach Text absuchen lassen, man kann nur einen kleinen Bereich umrahmen oder gar auf ein einzelnes Wort klicken. Dazu kann das Tool automatisch das Notepad mit dem kopierten Text darin aufrufen, sodass man diesen noch bearbeiten kann.
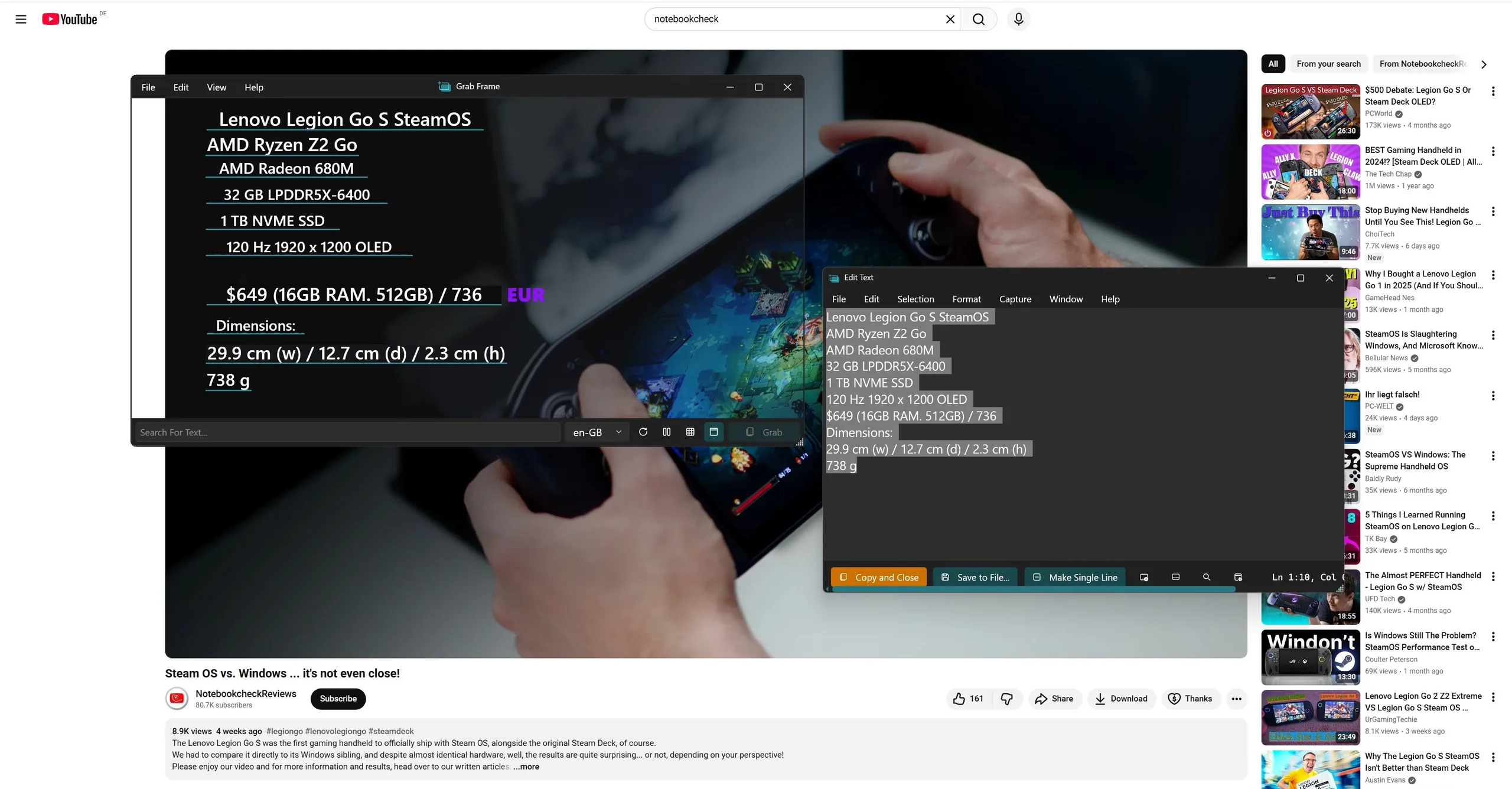
Und so funktioniert das Tool: Tatsächlich erstellt die App einen Screenshot und schickt diesen an die OCR Engine (OCR = Optical Character Recognition = Optische Zeichenerkennung), was in der lokalen Windows API abgewickelt wird.
Das Tool ist ziemlich zuverlässig, läuft lokal und ist Open Source. Ganz perfekt ist es aber auch nicht immer. Manchmal hat es bei meiner Verwendung Text auch falsch erkannt, da hilft dann aber die manuelle Nachbearbeitung im automatisch erscheinenden Editor.
